import praw
from datetime import datetime
import pandas as pd # para manipulación de dataframes
from dotenv import load_dotenv # cargar variables de ambiente
import os # cargar variables de ambienteLenguaje y género en Reddit: Contrastes entre r/AskMen y r/AskWomen
Métodos Computacionales para las Ciencias Sociales
Profesor: Klaus Lehmann M.
Ayudante: Matías Gallardo V.
Introducción
Reddit es una de las plataformas digitales más relevantes para la comunicación y discusión dentro de la Generación Z. Esta ofrece comunidades específicas (subreddits) que permiten al usuario crear, compartir y discutir contenido, y un ambiente de relativo anonimato donde se puede interactuar con contenido sensible y delicado. Siguiendo lo anterior, Reddit se vuelve una fuente valiosa de información sobre experiencias y discusiones en torno a diversas temáticas (Stang et al, 2025).
En este sentido, entendiendo que hoy en día la mayoría de las interacciones sociales se dan de forma digital, tanto el género como la sexualidad se comienzan a construir dentro de este ambiente. Así, los sujetos viven procesos de validación, pugna y normalización a través de las interacciones online con un otro globalizado. En consecuencia, el lenguaje, como expresión identitaria, también se construye a través de este medio, produciendo y reproduciendo roles y estereotipos de género. Esto refuerza las normas sociales y expectativas vinculadas a la identidad de género. (Criado et al, 2021; Sawicki & Solska, 2024; Scholz et al, 2025).
Con respecto a lo anterior, la relevancia sociológica de estudiar el género a través del lenguaje y las interacciones dentro de una plataforma digital como Reddit surge debido a la importancia que cumplen las redes sociales como principal espacio de socialización y construcción del género hoy en día. Además, este permite identificar y examinar discursos sesgados y dominantes, como también la producción y reproducción de estereotipos y roles. Así, se logra visibilizar la construcción del género a través de patrones sociolingüísticos y comunicativos. Por último, posibilita distinguir los diferentes perfiles de usuarios al interactuar con contenido propiamente ligado al género. A partir de esto, se formuló la siguiente pregunta de investigación: ¿Qué diferencias discursivas existen en torno al género en los comentarios de los usuarios de los subreddit r/AskMen y r/AskWomen en Reddit?
En el transcurso de la investigación se extraerá información de los subreddits de r/AskMen y r/AskWomen. Estos datos permiten, en primer lugar, una comparación y análisis de contenido a partir del género; en segundo lugar, un análisis cruzado, es decir, de qué se habla con respecto al género opuesto en cada subreddit; y, por último, un análisis de los diferentes perfiles de usuarios que interactúan en estos foros con respecto a su género e identidad. De esta forma, el estudio busca no solo identificar diferencias en los discursos de género entre ambos subreddits, sino también analizar las representaciones del género opuesto y los perfiles sociolingüísticos de los usuarios que participan en estas comunidades.
Fuente de información
La fuente de información donde se extrajeron los datos fue Reddit, específicamente los subreddits de r/AskMen y r/AskWomen.
AskMen fue creado el 30 de agosto de 2010. Es un espacio con alrededor de 2 millones de miembros y una participación activa de 41 mil contribuciones semanales. Su lema es “a place to discuss men’s experience”, demostrando ser un lugar para discutir y compartir vivencias desde la perspectiva masculina.
AskWomen, creado el 17 de julio de 2010, cuenta con más de 946 mil suscriptores y alrededor de 14 mil usuarios activos. Su propósito declarado es ofrecer un espacio donde las mujeres puedan responder con comodidad y sinceridad a preguntas sobre sus pensamientos, vidas y experiencias. Se enfatiza en el respeto y la ausencia de juicios, lo que lo convierte en un entorno distinto al de AskMen, con un enfoque más regulado hacia el tono y los temas de discusión.
Para la extracción de información de estos subreddits se utilizó la API de Reddit, mediante la librería PRAW. Esta herramienta permite automatizar la recolección de publicaciones y comentarios, asegurando un volumen considerable de datos y facilitando su análisis.
Tutorial
Extracción de información: API de Reddit
Como primer paso, fue necesario inscribir una aplicación para poder utilizar la API de Reddit. En el siguiente enlace se encuentra un tutorial detallado sobre cómo crear un app. A continuación, se muestra un ejemplo:
Autenticación con PRAW
Para interactuar con la API se trabajará en python, aprovechando las herramientas que ofrece este lenguaje. En este caso, se usa Positron como entorno de trabajo.
El primer paso consiste en importar las librerías necesarias: praw, datetime, pandas, dotenv y os.
Además, se requiere crear un text file con extensión .env donde se almacenan las credenciales de acceso. Si las variables dentro de este archivo se cargan correctamente, la función load_dotenv() devuelve True.
load_dotenv()Con lo anterior listo, se definen las variables que contienen los tokens del archivo .env. Las credenciales necesarias para la autenticación son: client_id, client_secret y user_agent.
client_id = os.getenv('CLIENT_ID')
client_secret = os.getenv('CLIENT_SECRET')
username = os.getenv('USERNAME')
password = os.getenv('PASSWORD')
user_agent = os.getenv('USER_AGENT')
auth_url = "https://www.reddit.com/api/v1/access_token"Finalmente, mediante la función reddit de praw, se realiza la conexión con la API utilizando las credenciales guardadas.
reddit = praw.Reddit(
client_id=client_id,
client_secret=client_secret,
user_agent=user_agent
)Proceso de extracción de datos
La extracción de datos se hizo a partir del los subreddits de r/AskMen y r/AskWomen. Para asegurar una cantidad de datos robusta, se sugiere una revisión sistemática de los subreddit y establecer criterios de extracción de datos.
Proceso de extracción de datos: r/AskMen
En primer lugar, se creó una variable que contiene el subreddit de donde se quiere extraer la información y una lista vacía para contener los comentarios de cada publicación
subreddit_askmen = reddit.subreddit("AskMen")
comentarios_askmen = []Posteriormente, se creó un for anidado. El primero refiere a la publicación, las cuales se filtraron las top por día, con un límite de 1000. El segundo, corresponde a los comentarios de cada publicación; para esto, se tuvo que añadir una línea de código para también extraer los códigos que están abajo del view more.
De esta forma, se recolectaron todos los comentarios de cada publicación del día en el subreddit. Además, la variable de tiempo se transformó de unix timestamp a datetime, lo que facilita su interpretación y análisis posterior.
for submission in subreddit_askmen.top(time_filter="day", limit=1000):
submission.comments.replace_more(limit=None)
for comment in submission.comments:
askmen = [
subreddit_askmen,
submission.author,
submission.id,
submission.title,
submission.num_comments,
submission.over_18,
submission.score,
comment.author,
comment.id,
comment.body,
comment.score,
datetime.fromtimestamp(comment.created_utc)
]
comentarios_askmen.append(askmen)Finalmente, se creó un dataframe que contiene las variables extraídas, asignándoles nombres para su identificación. A cada base de datos diaria se les asignó un nombre con el formato “nombresubreddit_fecha”, lo que permite organizarlas por día. Para efectos de este tutorial, los nombres de las bases de datos serán fecha “xxxx”.
askmen_xxxx = pd.DataFrame(
comentarios_askmen,
columns=["subreddit_nombre", "submission_autor", "submission_id", "submission_titulo",
"submission_numcom", "submission_NSFW", "submission_puntaje",
"comentario_autor", "comentario_id", "comentario_body", "comentario_puntaje", "comentario_fecha"]
)
askmen_xxxx.to_csv("askmen_xxxx.csv", index=False)Proceso de extracción de datos: r/AskWomen
El procedimiento se repitió de la misma manera, solamente cambiando el subreddit a r/AskWomen.
subreddit_askwomen = reddit.subreddit("AskWomen")
comentarios_askwomen = []
for submission in subreddit_askwomen.top(time_filter="day", limit=1000):
submission.comments.replace_more(limit=None)
for comment in submission.comments:
askwomen = [
subreddit_askwomen,
submission.author,
submission.id,
submission.title,
submission.num_comments,
submission.over_18,
submission.score,
comment.author,
comment.id,
comment.body,
comment.score,
datetime.fromtimestamp(comment.created_utc)
]
comentarios_askwomen.append(askwomen)
askwomen_xxxx = pd.DataFrame(
comentarios_askwomen,
columns=["subreddit_nombre", "submission_autor", "submission_id", "submission_titulo",
"submission_numcom", "submission_NSFW", "submission_puntaje",
"comentario_autor", "comentario_id", "comentario_body", "comentario_puntaje", "comentario_fecha"]
)
askwomen_xxxx.to_csv("askwomen_xxxx.csv", index=False)Unión de BBDD para procesamiento
A partir de este punto se comienza a trabajar con R, con el objetivo de facilitar la manipulación y visualización de datos. Para ello, se requiere instalar las liberías: dplyr, readr, tidyr, ggplot2, stringr y gt. Además, se evita la notación científica en los resultados y se limpia el entorno de trabajo.
library(dplyr) # Manipular datos
library(readr) # Leer datos
library(tidyr) # Tratamiento datos
library(ggplot2) # Gráficos
library(stringr) # Trabajar con texto
library(gt) # Tablas
options(scipen = 999)
rm(list = ls())Posteriormente, se cargan las BBDD guardadas en formato .csv y se unen todas en un único archivo denominado datos_ask. En caso de contar con más de un día de extracción, cada nueva base se debe ir incorporando de la misma manera. Finalmente, la base consolidada se guarda en un archivo con la función write_csv, lo que permite avanzar hacia el procesamiento de datos.
askmen_xxxx <- read_csv("askmen_xxxx.csv")
askwomen_xxxx <- read_csv("askwomen_xxxx.csv")
datos_ask <- bind_rows(askmen_xxxx, askwomen_xxxx)
write_csv(datos_ask, "datos_ask.csv")Procesamiento de BBDD en R
A partir de la base de datos consolidada se generó una versión procesada con nombre datos_ask_proc. En esta etapa se realizaron distintas transformaciones para mejorar la calidad de la información:
- la variable submission_NSFW fue recodificada de valores lógicos (False y True) a 0 y 1.
- la variable comentario_fecha se separó en fecha y hora, y se filtraron los días con menos de 100 observaciones.
- se filtraron los días con menos de 100 observaciones.
- Se filtraron las publicaciones que no obtuvieron comentarios.
- La variable fecha se reconoce como tipo date.
El resultado de este procesamiento corresponde a una base depurada, almacenada como datos_ask_proc.csv, que será la BBDD principal para el análisis posterior.
datos_ask_proc <- datos_ask %>%
mutate(submission_NSFW = case_when(
submission_NSFW == "FALSE" ~ 0,
submission_NSFW == "TRUE" ~ 1)) %>%
separate(comentario_fecha, into = c("comentario_fecha", "comentario_hora"), sep = " ") %>%
group_by(comentario_fecha)%>%
filter(n() > 100) %>%
ungroup()%>%
group_by(submission_id) %>%
filter(n() > 1)
as.Date(datos_ask_proc$comentario_fecha)
write_csv(datos_ask_proc, "datos_ask_proc.csv")Análisis
Variables
La base de datos procesada contiene un conjunto de variables que permite describir y analizar los contenidos de las publicaciones y comentarios de los subreddits a estudiar. En la siguiente tabla se presentan todas las variables incluidas en el análisis descriptivo, junto con una breve definición de su contenido y función dentro del dataset.
| Variables incluidas en el análisis | |
|---|---|
| Definición de cada variable del dataset procesado | |
| Variable | Definición |
| subreddit_nombre | Nombre del subreddit de donde proviene la publicación (AskMen o AskWomen). |
| submission_autor | Usuario que creó la publicación original. |
| submission_id | Identificador único de la publicación en Reddit. |
| submission_titulo | Título de la publicación realizada en el subreddit. |
| submission_numcom | Número total de comentarios que recibió la publicación. |
| submission_NSFW | Indica si la publicación fue marcada como NSFW (Not Safe For Work) (0=no, 1=sí). |
| submission_puntaje | Puntaje total de la publicación (upvotes – downvotes). |
| comentario_autor | Usuario que escribió el comentario. |
| comentario_id | Identificador único de cada comentario en Reddit. |
| comentario_body | Texto completo del comentario. |
| comentario_puntaje | Puntaje del comentario (upvotes – downvotes). |
| comentario_fecha | Fecha en que se realizó el comentario (formato día-mes-año). |
| comentario_hora | Hora en que se realizó el comentario. |
Análisis descriptivo
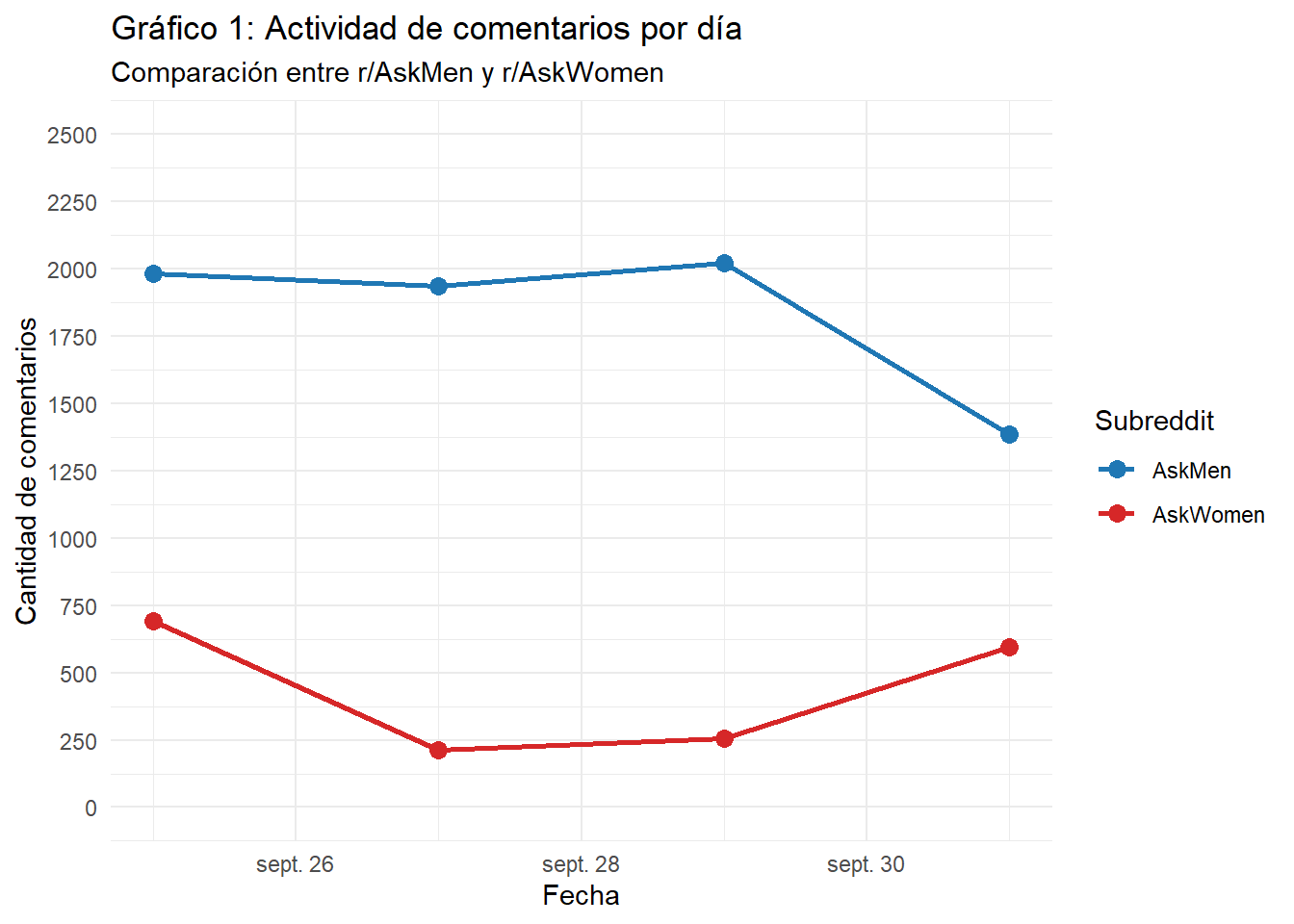
En la Tabla 1 se muestra la cantidad de comentarios en cada extracción por día y subreddit. Luego del procesamiento, el total de la base asciende a N = 9.085 comentarios. Como se observa en el Gráfico 1, la actividad diaria es consistentemente mayor en AskMen que en AskWomen, con una diferencia marcada que se mantiene a lo largo de los días analizados.
| Tabla 1: Comentarios por día | ||
|---|---|---|
| Cantidad de comentarios únicos en r/AskMen y r/AskWomen | ||
| Fecha | Subreddit | Comentarios |
| 2025-09-25 | AskMen | 1,984 |
| 2025-09-25 | AskWomen | 691 |
| 2025-09-27 | AskMen | 1,937 |
| 2025-09-27 | AskWomen | 214 |
| 2025-09-29 | AskMen | 2,023 |
| 2025-09-29 | AskWomen | 254 |
| 2025-10-01 | AskMen | 1,387 |
| 2025-10-01 | AskWomen | 595 |
| NA | Total | 9,085 |
La Tabla 2 presenta los estadísticos descriptivos de la cantidad de comentarios diarios. El promedio de AskMen (1.833) es más de cuatro veces superior al de AskWomen (438). Esto implica que, en promedio, por cada comentario en AskWomen, se registran cuatro en AskMen. Además, la variabilidad es mayor en AskMen, con un rango que llega hasta más de 2.000 comentarios, lo que indica mayor heterogeneidad en la actividad de este subreddit.
| Tabla 2: Estadísticos descriptivos | |||
|---|---|---|---|
| Descriptivos de comentarios diarios por subreddit | |||
| Subreddit | Media | Mínimo | Máximo |
| AskMen | 1,833 | 1,387 | 2,023 |
| AskWomen | 438 | 214 | 691 |
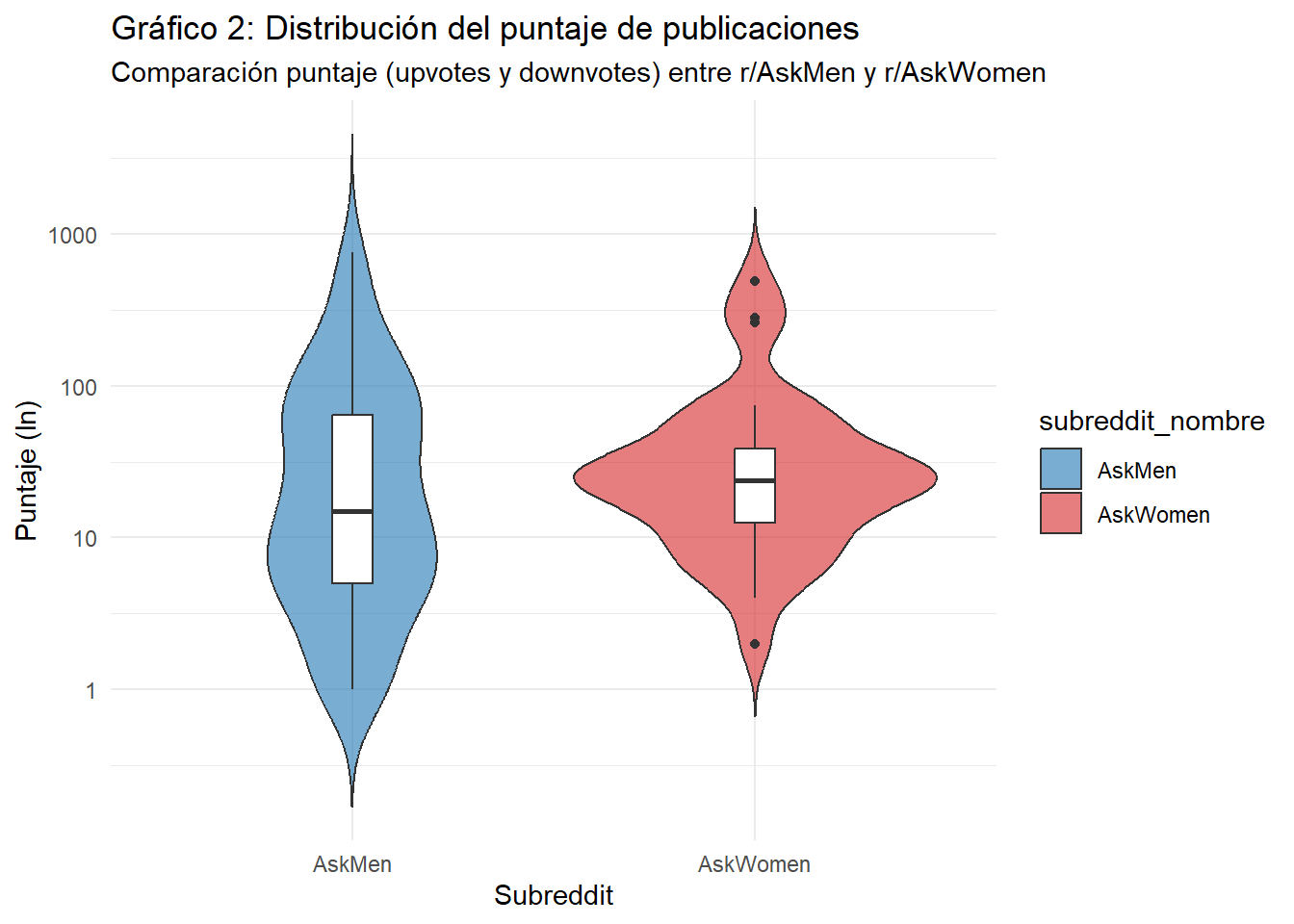
Respecto a las puntuaciones de las publicaciones, el Gráfico 2 evidencia una distribución con valores extremos más pronunciados en AskMen, donde aparecen publicaciones con puntajes considerablemente altos. En AskWomen, en cambio, las puntuaciones tienden a concentrarse en un rango más reducido, lo que sugiere un comportamiento más homogéneo en las interacciones de los usuarios.
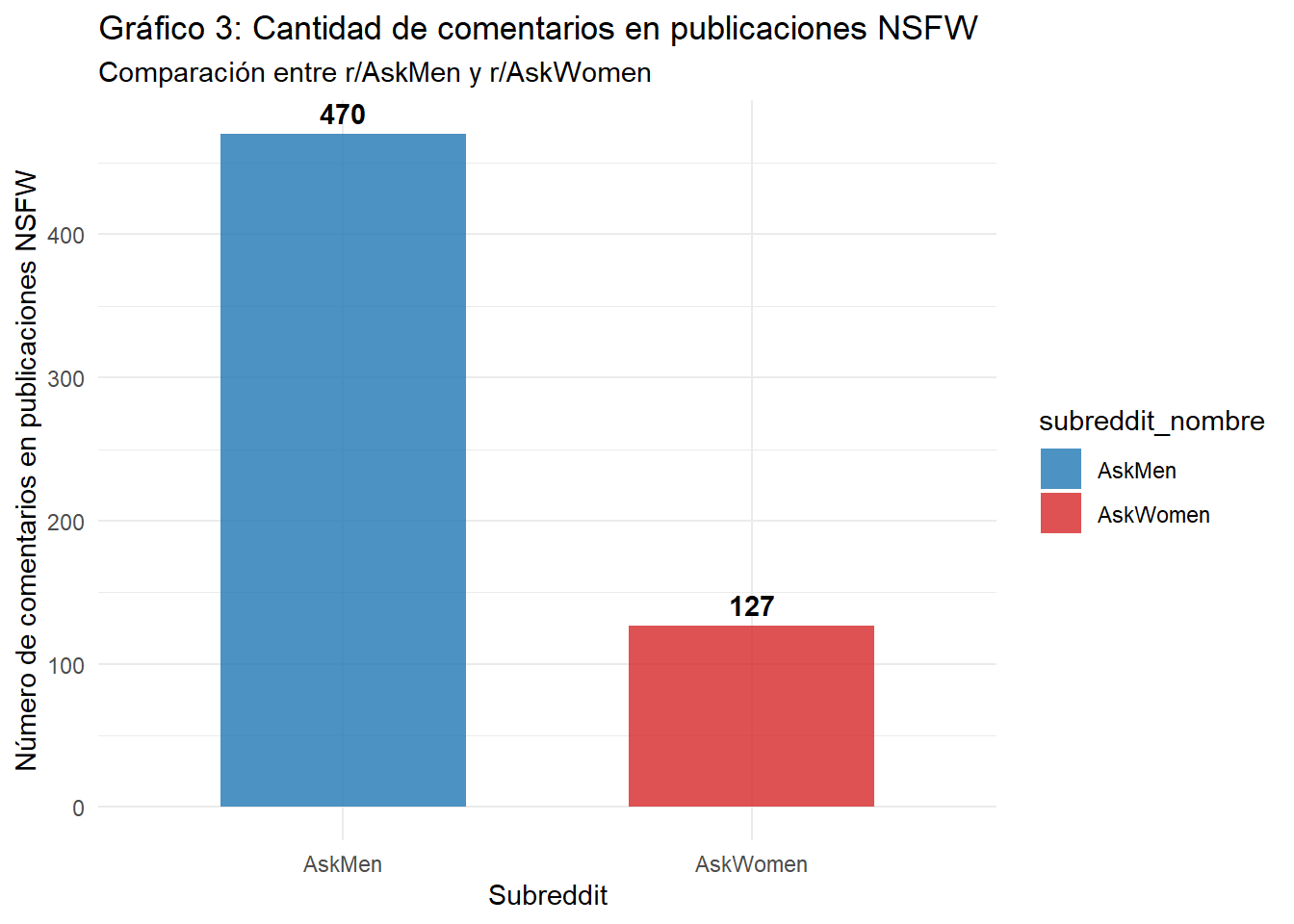
En el caso del contenido marcado como NSFW (Not Safe For Work), el Gráfico 3 muestra una diferencia significativa: en AskMen se contabilizan 470 comentarios en publicaciones NSFW, mientras que en AskWomen son solo 127. Este resultado refuerza la idea de que AskMen concentra una mayor proporción de interacciones asociadas a material sensible o explícito.
Directrices de investigación
Para la investigación a futuro, se busca realizar un análisis específico de contenido con respecto al género. Por ejemplo, de insultos, contenido sexual, emociones, entre otros.
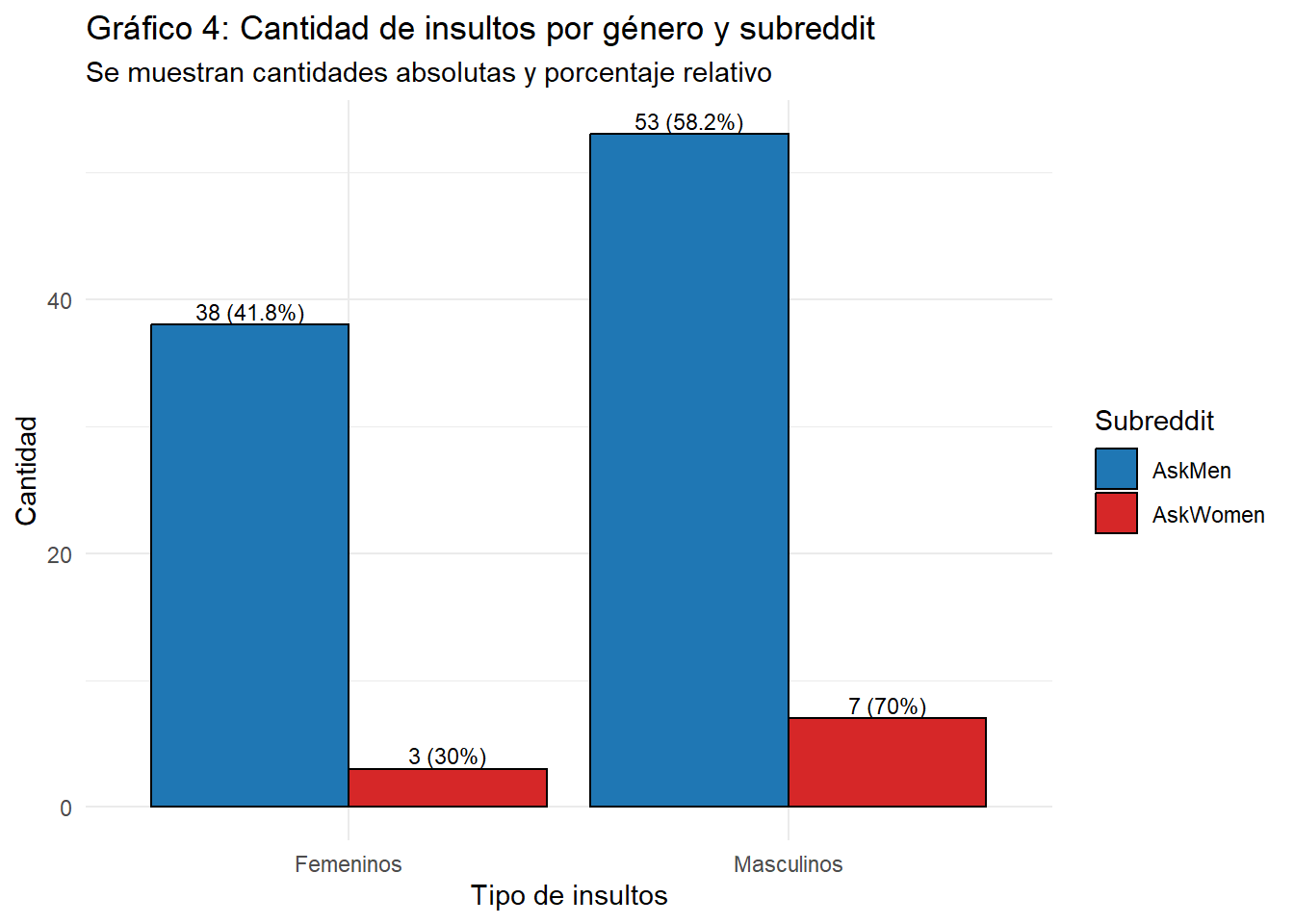
En el Gráfico 4 se presenta un análisis preliminar sobre el uso de insultos hacia hombres y mujeres en los comentarios. En ambos subreddits se observa la presencia de lenguaje ofensivo, pero destaca que en AskMen se identifican más insultos dirigidos tanto a hombres (58,2%) como a mujeres (41,8%). En AskWomen, en cambio, los insultos aparecen en menor frecuencia, aunque con un sesgo marcado hacia insultos de carácter masculino (70%).
Conclusión
A modo de síntesis, se puede señalar que la actividad en AskMen es mucho mayor que en AskWomen, con cerca de cuatro veces más comentarios diarios. Además, las publicaciones en AskMen presentan puntajes más extremos, mientras que en AskWomen tienden a concentrarse en un rango más homogéneo.
El contenido NSFW es más frecuente en AskMen, lo que refleja diferencias en las formas discursiva de cada comunidad.
Finalmente, los insultos aparecen con mayor intensidad en AskMen, tanto hacia hombres como hacia mujeres. En AskWomen son menos frecuentes, aunque con un sesgo hacia insultos dirigidos a lo masculino.
En conjunto, AskMen se caracteriza por un volumen de interacciones más alto, dinámicas discursivas más polarizadas, reflejado en sus puntajes, y mayor presencia de lenguaje sensible, mientras que AskWomen muestra menor actividad y un discurso más homogéneo.
Referencias bibliográficas
Criado, N., Ferrer, X., Such, J. & Van Nuenen, T. (2021). Discovering and Categorising Language Biases in Reddit. Proceedings of the International AAAI Conference on Web and Social Media, 15(1), 140-151. https://doi.org/10.1609/icwsm.v15i1.18048
Sawicki, J. & Solska, D. (2024). Decoding gender bias through a textual exploration of Reddit /r/MensRights community. Beyond Philology, 1(21), 167-202. https://doi.org/10.26881/bp.2024.1.06
Scholz, S., Stang, P., Weiss, M. & Winkler, C. (2025). Changing Conversations: The Rise of Gender and Sexuality Discourse on Reddit. Arch Sex Behav, 54, 1–5. https://doi.org/10.1007/s10508-024-03051-9